- Automatically extracts data from websites.
- Ensures relevant and updated content.
1
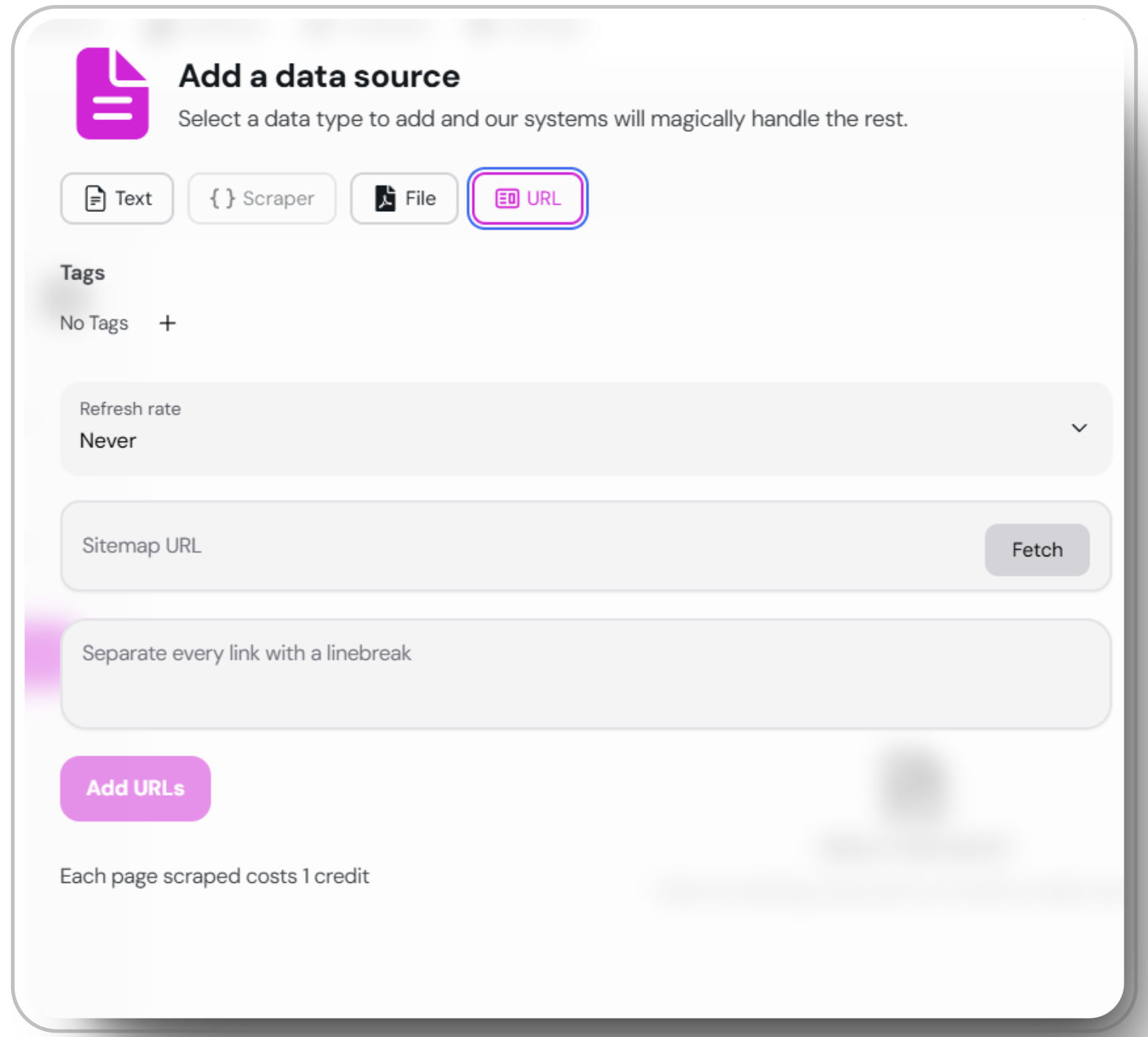
Select 'URL' in the Add Data Source Window
Open the
add data source window and choose the “URL” option.2
Enter the URL or Sitemap
Input the URL or sitemap you want to scrape. Press
fetch to retrieve and review the sitemap from the XML file.3
Scrape the Data
Once the URLs are fetched, scrape the data and save it as individual documents. Scroll through and remove any unwanted information to ensure relevance.
Using the URL scraper will use X credits per page. Please ensure your account has sufficient credits.
Regularly check the extracted data for relevance and accuracy to maintain a high-quality knowledge base.