How the Crawler Works
The crawler operates by systematically visiting web pages, extracting relevant content, and organizing it into makrdown suitable for your agent’s knowledge base. This process involves crawling through links, scraping text, and formatting the data for optimal use by AI models.
Crawler Jobs
The core of the crawler functionality revolves around crawler jobs. Each job is associated with specific source URLs you want to crawl and is identified by a unique ID. The developer API offers several ways to interact with the crawler.Job Details UI
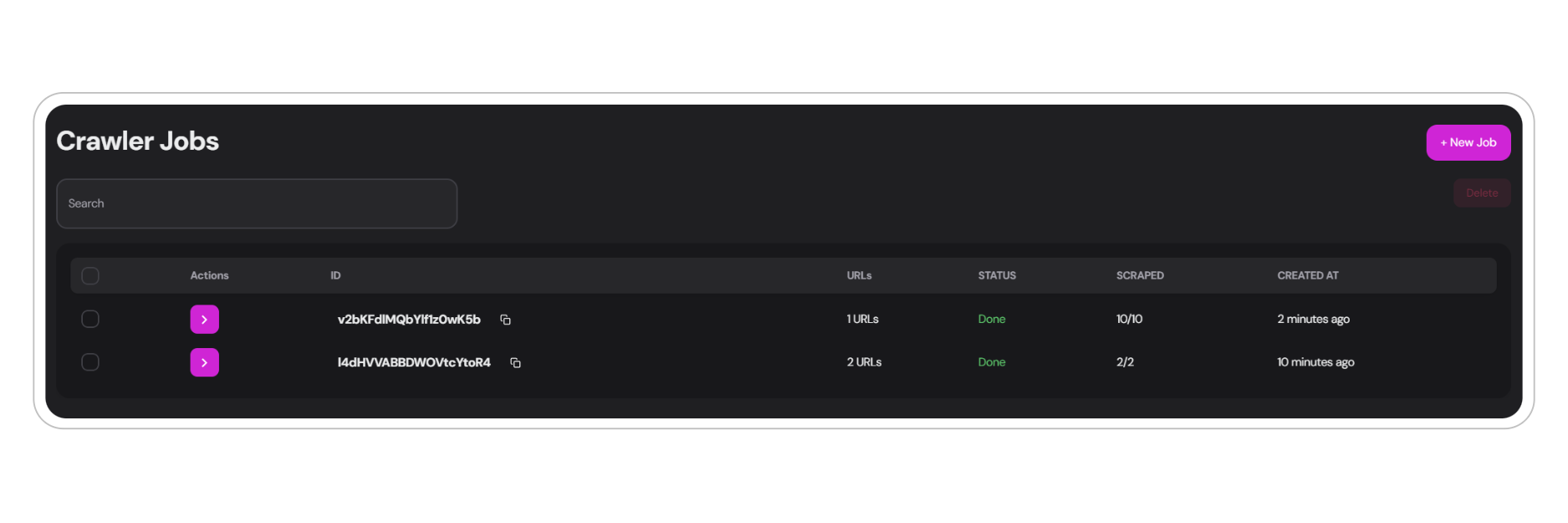
Creating a New Crawler Job
To initiate a new crawler job, follow these steps:1
Set Source URLs
Navigate to the crawler tab from the menu on the left side of your dashboard. Click on
new job and Enter the main URL(s) you want the crawler to begin with (e.g., https://www.tixaeagents.ai).Ensure you use valid URLs in the correct format: https://example.com
2
Configure Crawl Settings
There are two options to consider that determines the quality of the scrape:
Regular crawl
Regular crawl
- Default option, costs 1 credit per page scraped.
Deep crawl
Deep crawl
- Autoscrolls and forces loading of images for better quality. Costs 10 credits per page.
3
Refresh Rate
Set Crawler Refresh Rate
The crawler refresh rate determines how often the crawler will update the current job with potential new information from the scraped site. This is particularly useful for websites that update frequently, such as e-commerce sites.You can create separate crawler jobs for different sub-pages. This allows you to set different refresh rates for various sections of a website. For example, on a Shopify site, you might want to update
/collections/protein-powder more frequently than the main page, as product information changes more often.Available Refresh Rate Options:
Refresh Rates
4
Specify Page Limit
Set the maximum number of pages to scrape for that job, ranging from 10 up to 500 pages.
Review the sitemap beforehand to determine the optimal number of pages to scrape. To view, write
/sitemap.xml at the end of a valid URL. Ex. https://www.tixaeagents.ai/sitemap.xml or use this5
Define URL Patterns
Match URLs: Include subpages you want to scrape based on the source URL.
Example: Match URLs
Example: Match URLs
Unmatch Patterns: Specify URLs or patterns to exclude from the scrape.
Example: Unmatch Patterns
Example: Unmatch Patterns
Coming soon: Ability to assign crawl jobs directly to specific agents for automatic knowledge base updates.
Scraped Pages
After completing a crawler job, you can review and manage the scraped pages in the jobs dedicated interface. This section provides an overview of all pages collected during the job and status messages, such as when the maximum page limit is reached or when the crawler is active.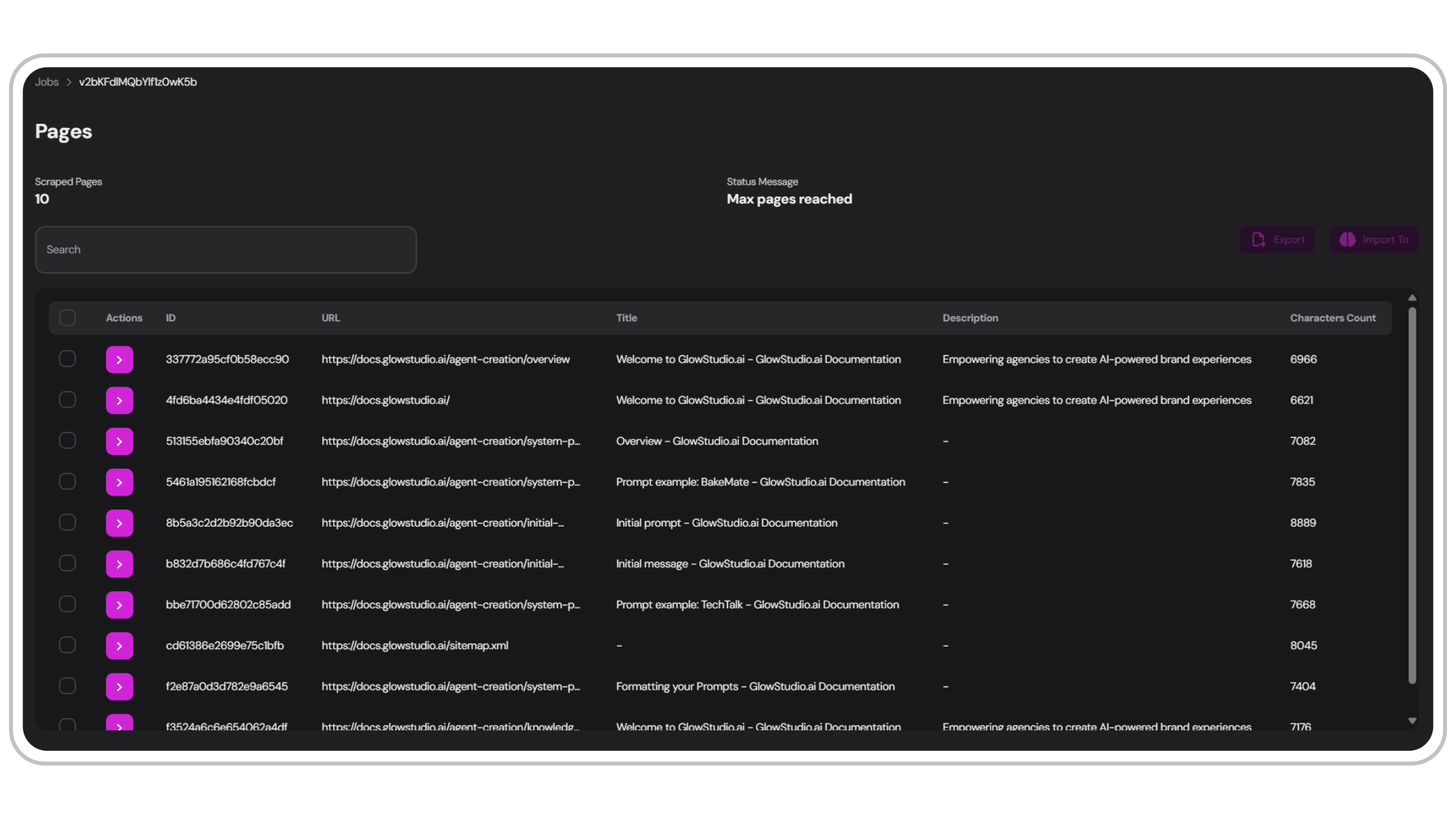
The pages view provides:
Unique document ID
Unique document ID
A distinct identifier for each scraped page
URL
URL
The web address of the scraped page
Title
Title
The main title of the document
Description
Description
A brief summary of the page content
Character count
Character count
The total number of characters in the scraped document
Managing Scraped Pages
You can perform the following actions on the scraped pages:Select Pages
Check the pages you want to process further
Export
Download selected pages as a zip file containing .txt documents
Import
Add selected pages to the knowledge base of your chosen agent
Scraped Page Data
The scraped page data shows a detailed view of each page scraped in the job: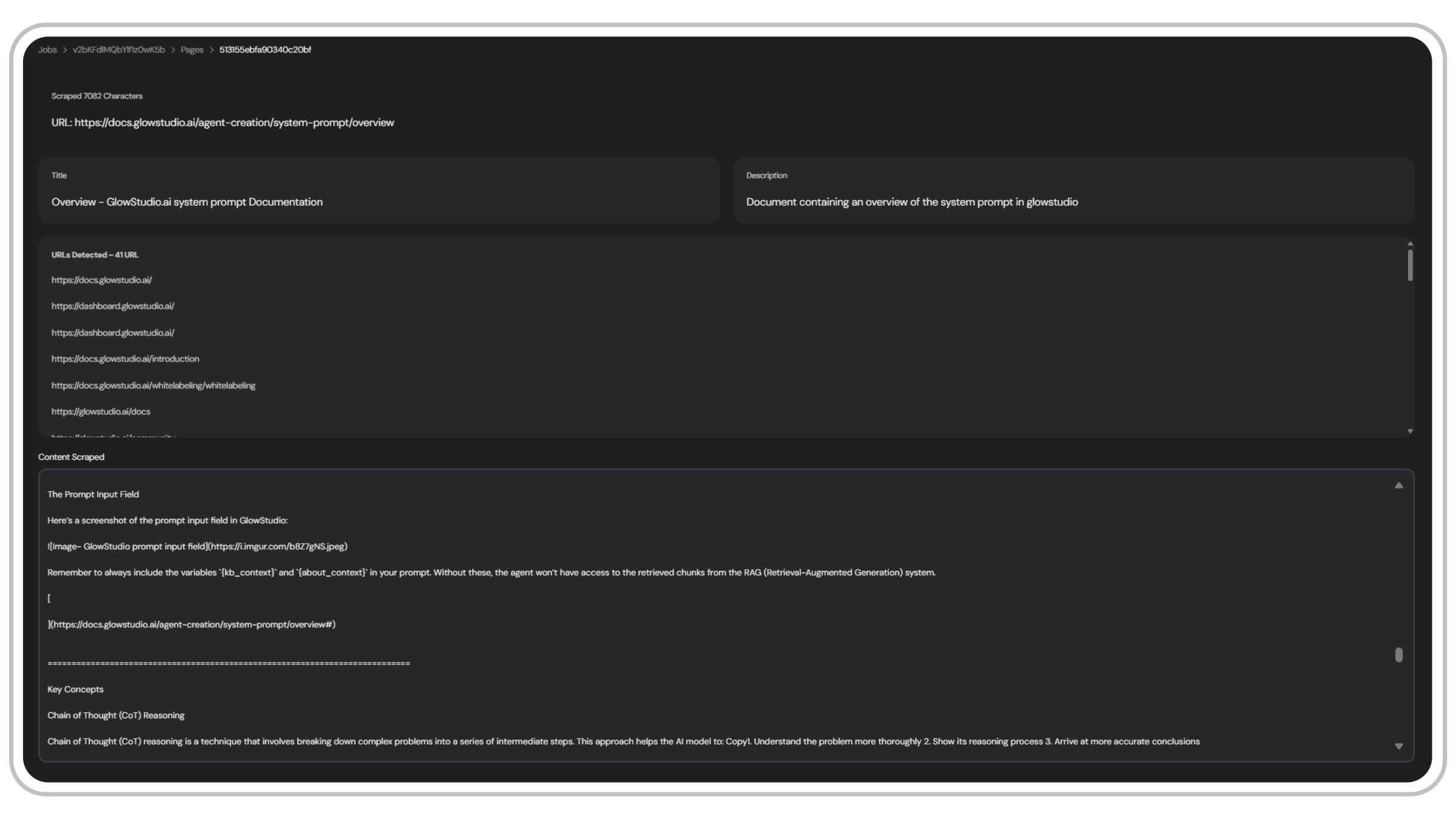
The page data view provides:
URL
URL
The web address of the scraped page
Title
Title
The main title of the page
Description
Description
A descriptive sentence that works as a summary of the page content and provides context to the LLM when retrieving from the knowledge base.
Detected URLs
Detected URLs
Links found within the scraped page
Content
Content
The main text scraped from the page, formatted in markdown
Example snippet of scraped information in markdown:
Scraped information is formatted in markdown for easy reading by LLMs. To learn more about formatting KB documents, visit the formatting doc.
Crawler Job Status
When you initiate a new crawler job, it will progress through several status stages:- Pending: The crawler has started and is in the process of gathering URLs and scraping content.
- Active: The crawler is actively scraping pages.
- Completed: The job has finished, and all specified pages have been scraped.
You will receive a notification in the dashboard when the job status changes to
Completed.Best Practices and Tips
Optimize URL Patterns
Carefully define match and unmatch patterns to focus on the most relevant content.
Monitor Credit Usage
Remember that each page scraped costs credits (1 for normal, 10 for deep scrape).
Regular Updates
Set appropriate refresh rates for dynamic content to keep your knowledge base current.
Review Before Import
Always review scraped content before importing it into your agent’s knowledge base.